elements

As much as struggle with on-device processing and the quality of its output compared to server models, I am excited by some of the APIs that are being built into browsers that are backed by LLMs and other AI inference models.
For example, the prompt API, along with a multi-modal version that can take any arbitrary combination of text, image, and audio and run prompts against them. These APIs are neat but not yet web-exposed and many developers struggle to know what to do with a generic prompt. It’s not a solution that is natural to many people yet.
To solve this, Chrome introduced a host of use-case-based APIs into the browser. These APIs, such as Summarizer, Writer and Rewriter, Translate and Language Detection are designed to run within web content. An API designed to solve a particular problem is easier to standardize and build consensus around. It also makes it clearer for web developers and business owners to see how they might integrate it into their businesses.
For example, while building this blog (it’s Hugo-based), I would checkpoint my work by committing it to my Git repo. I realized that many products are subtly integrating AI into their experiences. For example, when you check something into your repo, a small star icon generates a commit message based on the changes. I use this all the time now because it beats my “asdf” messages hands-down.
AI Summarize a set of github commits
This is a use-case that I think is easy for people to understand.
While sharing a recent post, I saw a Tweet from my friend Eiji that was in Japanese, but I could still read it because a “Translate” link appeared within the text.
Translate Tweet
Again, another use-case that is easy to understand.
This got me thinking. It’s great that you can use JavaScript to wrangle these high-level APIs, but it also made me consider if there are even higher-level abstractions that we should be thinking about, like HTML.
It feels like there is a massive opportunity to either imbue existing elements and components with these capabilities or even to conceive of new elements altogether, and it’s something that I think we should talk about more.
With this in mind, I’ve created three simple examples: Summarize and Translate and Image picking.
The summarize element’s goal is to act like the commit message generator in VS Code. You provide the ID of an element to watch for changes, and it will summarize the content. The best part is that it uses InternalElements to enable the element to participate in <form> submissions.
<ai-summarize-component watch="longTextElement"></ai-summarize-component>
<textarea id="longTextElement" name="text" rows="4" cols="50"></textarea>

AI Summarize a textarea
The translate element is a HTMLParagraphElement that detects the language of its content and then offers to translate it into the user’s preferred language. It uses both the Translate API and LanguageDetection API to do this.
<ai-translate-component>
私はティーポットです と とても幸せです
</ai-translate-component>

AI Translate a paragraph Element
Maybe we will finally get an answer to the bug I filed years ago about Google Translate breaking React as developers will have a way to integrate translation into their apps exactly as they need it, versus the shotgun approach of the current Google Translate in Google Chrome.
I also like to think about how form elements might integrate with technologies like generative LLMs. For example, consider the humble <input type="file" accept="image/png" />. If we assume image generation is here to stay, should we consider enabling deeper integration into the file and content pickers? If so, this would mean you no longer have to generate an image in one app, download it, find it, and then upload it.
Well, <ai-image-input> is a demo of an optimization for that.
<form id="imageInputForm">
<ai-image-input name="image"></ai-image-input>
<input type="submit" />
</form>
It acts like a normal form element, but when you press Option (on a Mac), a new set of features is enabled, allowing you to attach an image generated from a prompt. Note that there is no on-device generation in this demo; it’s handled by a server.

AI Image Input Element Demo
I think the file input is a very neat use case that could be extended to video. It also reminds me of one of the goals of Web Intents: allowing deeper integration of the browser with system services and user-preferred applications, eliminating the need to leave the browser, download a file, and then re-upload it.
There’s a lot of other user interface features that I could imagine that would be useful to have as a built-in part of the platform. For example:
<a href="https://paul.kinlan.me" summarize>could enable the user agent to fetch the URL and summarize it for the user. Given CSP and other security concerns, this would be something only a user agent provided element could manage today.<a href="..." extract-info="recipe-time">could display “Cook time: 45 mins” on hover or inside the element if the link points to a recipe, or<a href="..." extract-info="product-price">could show the price and rating for a product link.<a href="asdf.com" clarify-purpose>Click here</a>might be an interesting way to turn a vague link text like “Click here” or “Read more,” because the browser could fetch the destination’s content to generate a more descriptive label for screen readers (this might just be a good thing for an extension to do instead)<a href="asdf.com" add-to-calendar>Event page</a>would be fun if you know if the link points to an event page, the browser could parse it for a date, time, and location and present a native UI to add the event to the user’s default calendar streamlining a common, multi-step process.<input type="file" extract="invoice-details">could allow a user to upload a PDF of an invoice, and the browser could use an LLM to automatically parse and populate fields for the date, amount, and vendor, simplifying expense reporting or data entry tasks.<input type="text" transcribe>could enable the user agent to transcribe audio into text by offering a microphone button that would record audio.- Should we have a dedicated
<input type="prompt">or<input type="chat">that might offer a user affordance like<input type="search">offers, could it hook into a user-configured default chat provider? - An attribute like
<img identify-objects>could allow the browser to recognize objects within an image and then expose them as to the user as a list of tags or descriptions, enhancing accessibility and searchability. - A
<video describe>attribute could automatically generate and voice an audio description of the visual events happening on screen, not just closed captions as a transcription. - A textarea could be enhanced with an attribute that hints at the type of content expected, like
<textarea suggestions="creative-writing">or<textarea suggestions="code-completion">. Much like how you can tell the browser the type of input mode, the browser could then offer context-aware autocompletion or creative prompts to help the user.
Update After posting this, I also experimented with an <ai-date-component> that let’s you write a date in natural language and it will parse it into a date object.
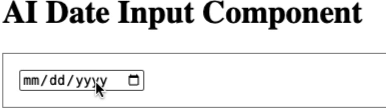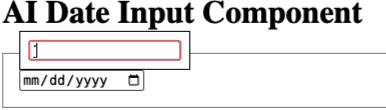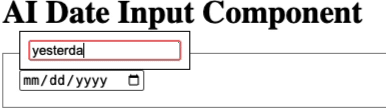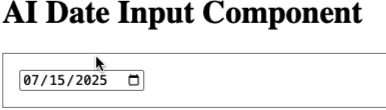
AI Date Component Demo
End Update
Should the default elements be imbued with AI capabilities? Or should these all just live in user-land as custom-elements or Components in the framework of your choice? We certainly are starting to get more of the technology to do this all in the browser, whether it’s the improvements to Web Components or the new AI-based APIs, but I don’t actually know the answer.
I do believe that this is an that we need a lot more discussion around and is something browser vendors and spec authors should really starting to think about it too.
The source to the demo web components is available on my github: https://github.com/PaulKinlan/ai-wc